otter二次开发-支持分库分表
otter二次开发-支持分库分表
# 一、背景
在某些业务场景下,需要将一张表的数据按照某个字段取模后,插入到不同的分表,但是otter不支持分表同步逻辑(源:offer , 目:offer[1-128]),因此对otter进行二次开发,使其支持分库分表功能
# 二、分库分表支持
基于otter-4.2.18 (opens new window)改造,变更如下:
核心代码逻辑
private String buildNameSharding(EventData data, DataMediaPair pair) {
ModeValue targetModeValue = pair.getTarget().getNameMode();
//获取源表的所有字段,看源字段是否存在
List<EventColumn> allColumns = new ArrayList<EventColumn>();
allColumns.addAll(data.getKeys());
allColumns.addAll(data.getColumns());
String shardValue = null;
//获取分库分表路由字段的值
for (EventColumn eventColumn : allColumns) {
if (eventColumn.getColumnName().equalsIgnoreCase(pair.getShardingKey())) {
shardValue = eventColumn.getColumnValue();
break;
}
}
//如果分库分表字段为null
if (shardValue == null) {
throw new RuntimeException("分表字段:{" + pair.getShardingKey() + "}为null,eventData:{" + data + "}");
}
List<String> tmp = targetModeValue.getMultiValue();
int index = Integer.valueOf(shardValue) % tmp.size();
return tmp.get(index);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
数据字段变更
ALTER TABLE data_media_pair ADD IS_SHARDING_JDBC TINYINT DEFAULT 0 NOT NULL COMMENT '是否分库分表,0否 1是' AFTER `FILTER`;
ALTER TABLE data_media_pair ADD SHARDING_KEY varchar(100) NULL COMMENT '分库分表列名' AFTER IS_SHARDING_JDBC;
1
2
2
完整代码提交记录:https://github.com/HeyouA/otter/commit/7d6b1e359538a59c3f5ecc223858eafbc88811a8
源码编译
mvn clean package -Dmaven.test.skip -Denv=release1
# 三、分库分表功能验证
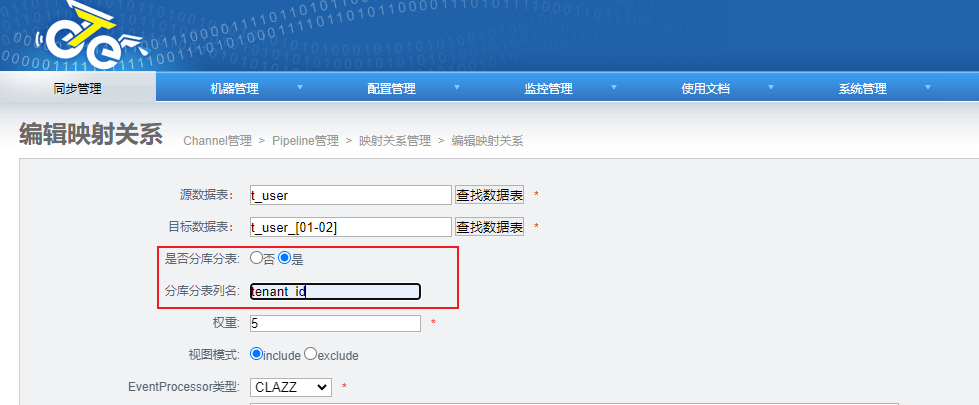
验证testotter1.t_user按照字段tenant_id取模后同步到分表testotter3.t_user_01和testotter3.t_user_02
step1:数据初始化
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `testotter1` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `testotter3` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */;
CREATE TABLE testotter1.`t_user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '用户id',
`tenant_id` int NOT NULL COMMENT '租户id',
`name` varchar(32) DEFAULT NULL COMMENT '名称',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_update_time` (`update_time`) USING BTREE,
KEY `idx_create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户表';
CREATE TABLE testotter3.`t_user_01` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '用户id',
`tenant_id` int NOT NULL COMMENT '租户id',
`name` varchar(32) DEFAULT NULL COMMENT '名称',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_update_time` (`update_time`) USING BTREE,
KEY `idx_create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户表';
CREATE TABLE testotter3.`t_user_02` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '用户id',
`tenant_id` int NOT NULL COMMENT '租户id',
`name` varchar(32) DEFAULT NULL COMMENT '名称',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_update_time` (`update_time`) USING BTREE,
KEY `idx_create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户表';
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
step2:创建同步链路和映射关系
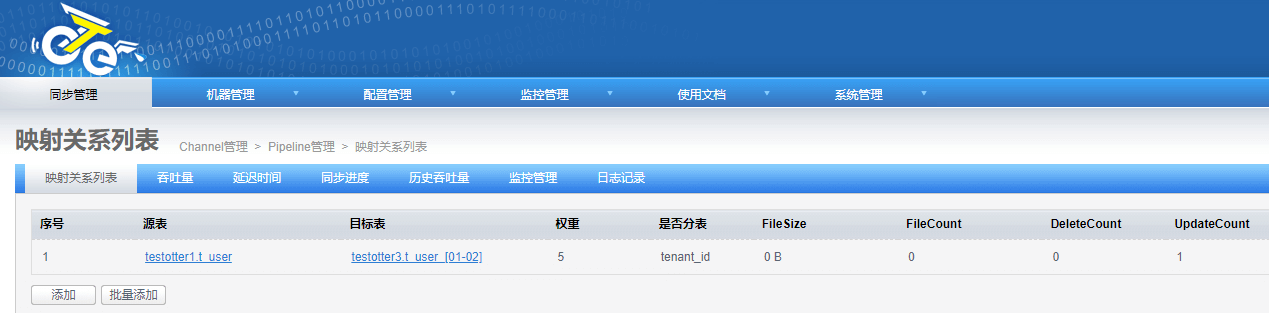
step3:同步验证
#插入测试数据
insert into testotter1.`t_user`(name,tenant_id) values("元月1",1);
#可以看到目标库已有数据
select * from testotter3.`t_user_01`;
select * from testotter3.`t_user_02`;
1
2
3
4
5
2
3
4
5
# 四、FAQ
# 4.1、分表同步的DDL语句暂不支持
目前分表同步的DDL语句暂未做支持,在生产环境,我们一般会关闭ddl同步,因为考虑到生产环境数据库表字段(大表)的变更,如果使用otter的ddl的同步变更,会出现长时间锁表等灾难性问题。因此建议在创建pipeline的时候,关闭支持ddl同步功能