
 一条SQL的平凡之路--优化篇
一条SQL的平凡之路--优化篇
# 一条SQL的平凡之路--优化篇
# 一、SQL优化思路
# 1.1、慢SQL日志开启
临时开启
# 查看慢sql是否开启
show VARIABLES like 'slow_query_log';
# 开启慢sql日志
set global slow_query_log='ON';
# 慢sql收集阈值查询(单位秒)
show VARIABLES like 'long_query_time';
# 慢sql收集阈值修改(需要重启数据库才能生效)
set global long_query_time = 2;
# 查看慢sql查询日志文件保存位置
show VARIABLES like 'slow_query_log_file';
# 设置慢sql查询日志文件保存位置
set GLOBAL slow_query_log_file='/data/local/mysql/log/mysql-slow.log';
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
my.cnf配置文件开启
[mysqld]
# 开启慢SQL查询日志
slow_query_log=1
# 慢SQL日志文件的位置
slow_query_log_file=/data/server/data/mysql-slow-2022-07-09.log
# 慢SQL的时间阈值。超过long_query_time设定的,就会记录到/data/server/data/mysql-slow.log日志文件中
long_query_time=3
# sq执行中Rows_examined扫描行数必须大于500才会记录
min_examined_row_limit =500
# 没有使用索引的SQL或虽然使用了索引但仍然遍历了所有记录的SQL,记录到慢查询日志
log-queries-not-using-indexes
# 没有使用索引的SQL每分钟记录的次数 即:为了节省空间 同一条SQL语句在一分钟内最多只记录10次
log_throttle_queries_not_using_indexes =10
# 记录执行缓慢的管理SQL,例如alter table|analyze table|check table|create index|drop index|optimize table|repair table 等命令
log-slow-admin-statements = table
# 记录从库上执行的慢查询语句
log_slow_slave_statements
# 记录慢查询日志的格式 FILE|TABLE|NONE 默认是文件格式 TABLE 是以表的格式 不建议用table
log_output = file
# 慢日志记录的时间格式 采用系统的时间
log_timestamps = 'system'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 1.2、Explain查看SQL的预执行计划
当我们执行了如下一条SQL,效果如下
explain select * from actor;

我们需要重点关注id、type、key、rows、extra
# 1.2.1、id列
有几个 select 就有几个id,id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行
# 1.2.2、type列
表示关联类型或访问类型, 从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL
一般来说,得保证查询达到range级别,最好达到ref
NULL mysql能够在优化阶段分解查询语句,在执行阶段不用再访问表或索引。
在索引列中选取最小值,可以单独查找索引来完成,不需要在执行时访问表
explain select min(id) from film;1
const, system const用于 primary key 或 unique key 最多有一个匹配行。system是const的特例,表里只有一条元组匹配时为system
explain extended select * from (select * from film where id = 1) tmp;1
show warnings;1
eq_ref primary key 或 unique key 索引的所有部分被连接使用 ,最多只会返回一条符合条件的记录
explain select * from film_actor left join film on film_actor.film_id = film.id;1
ref 相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀
-- 简单 select 查询,name是普通索引(非唯一索引) explain select * from film where name = 'film1';1
2
-- 关联表查询,idx_film_actor_id是film_id和actor_id的联合索引,这里使用到了film_actor的左边前缀film_id部分。 explain select film_id from film left join film_actor on film.id = film_actor.fi lm_id;1
2
range 范围扫描通常出现在 in(), between ,> ,<, >= 等操作中
explain select * from actor where id > 1;1
index 扫描全索引就能拿到结果,一般是扫描某个二级索引,直接对二级索引的叶子节点遍历和扫描,速度还是比较慢的,这种查询一般为使用覆盖索引,二级索引一般比较小,所以这种通常比ALL快一些。
explain select * from film;1
ALL 即全表扫描,扫描你的聚簇索引的所有叶子节点
explain select * from actor;1
# 1.2.3、key列
这一列显示mysql实际采用的索引。 如果没有使用索引,则该列是 NULL。
如果想强制mysql使用或忽视possible_keys列中的索引,在查询中使用 force index、ignore index。
# 1.2.4、rows列
这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数。
# 1.2.5、Extra列
Using index:使用覆盖索引
## `film_id`字段建了二级索引 explain select film_id from film_actor where film_id = 1;1
2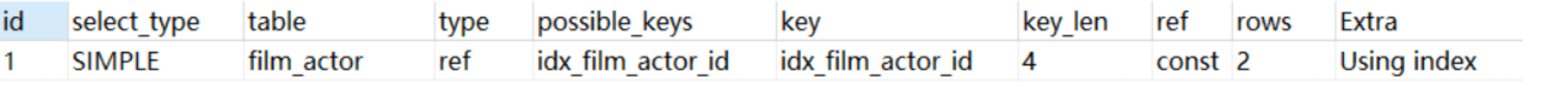
Using where:使用 where 语句来处理结果,并且查询的列未被索引覆盖
explain select * from actor where name = 'a';1
Using index condition:查询的列不完全被索引覆盖,where条件中是一个前导列的范围;
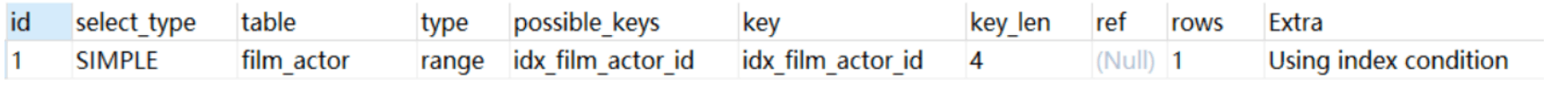
Using temporary:mysql需要创建一张临时表来处理查询。需要用索引来优化
explain select distinct name from actor;1
Using filesort:将用外部排序而不是索引排序
-- actor.name未创建索引 explain select * from actor order by name;1
2
Select tables optimized away:使用某些聚合函数(比如 max、min)来访问存在索引的某个字段
explain select min(id) from film;1
# 1.3、profile分析SQL执行耗时和资源占用
-- 查看是否开启
show variables like 'profiling%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| profiling | OFF |
| profiling_history_size | 15 |
+------------------------+-------+
-----------------------------------
-- 开启profiling
set profiling=1;
-- 查看SQL执行情况
show profiles;
+----------+------------+------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+------------------------------------+
| 1 | 0.00018100 | show variables like 'profiling%' |
| 2 | 0.00020400 | show variables like 'profiling%' |
| 3 | 0.00007800 | set profiling=1 |
| 4 | 0.00011000 | show variables like 'profiling%' |
| 5 | 0.00002400 | select count(1) from `actor` |
| 6 | 1.52181400 | select count(*) from `actor` |
| 7 | 0.00026900 | show variables like 'profiling%' |
--------------------
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 1.4、optimizer_trace 跟踪SQL的解析优化过程
它可以跟踪SQL的解析优化执行的全过程。
set session optimizer_trace="enabled=on",end_markers_in_json=on;
‐‐开启trace 2
select * from employees where name > 'a' order by position;
SELECT * FROM information_schema.OPTIMIZER_TRACE;
2
3
4
整个过程包括三个阶段:
- join_preparation:准备阶段
- join_optimization:分析阶段
- join_execution:执行阶段
{
"steps": [
{
"join_preparation": { --第一阶段:SQL准备阶段,格式化sql
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `employees`.`id` AS `id`,`employees`.`name` AS `name`,`employees`.`age` AS `age`,`employees`.`position` AS `position`,`employees`.`hire_time` AS `hire_time` from `employees` where (`employees`.`name` > 'a') order by `employees`.`position`"
}
] /* steps */
} /* join_preparation */
},
{
"join_optimization": { --第二阶段:SQL分析阶段
"select#": 1,
"steps": [
{
"condition_processing": { --条件处理
"condition": "WHERE",
"original_condition": "(`employees`.`name` > 'a')",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(`employees`.`name` > 'a')"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(`employees`.`name` > 'a')"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(`employees`.`name` > 'a')"
}
] /* steps */
} /* condition_processing */
},
{
"substitute_generated_columns": {
} /* substitute_generated_columns */
},
{
"table_dependencies": [ --表依赖详情
{
"table": "`employees`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
] /* depends_on_map_bits */
}
] /* table_dependencies */
},
{
"ref_optimizer_key_uses": [
] /* ref_optimizer_key_uses */
},
{
"rows_estimation": [ --预估表的访问成本
{
"table": "`employees`",
"range_analysis": {
"table_scan": { --全表扫描情况
"rows": 10123, --扫描行数
"cost": 2054.7 --查询成本
} /* table_scan */,
"potential_range_indexes": [ --查询可能使用的索引
{
"index": "PRIMARY", --主键索引
"usable": false,
"cause": "not_applicable"
},
{
"index": "idx_name_age_position", --辅助索引
"usable": true,
"key_parts": [
"name",
"age",
"position",
"id"
] /* key_parts */
}
] /* potential_range_indexes */,
"setup_range_conditions": [
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
} /* group_index_range */,
"analyzing_range_alternatives": { --分析各个索引使用成本
"range_scan_alternatives": [
{
"index": "idx_name_age_position",
"ranges": [
"a < name" --索引使用范围
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": false, --使用该索引获取的记录是否按照主键排序
"using_mrr": false,
"index_only": false, --是否使用覆盖索引
"rows": 5061, --索引扫描行数
"cost": 6074.2, --索引使用成本
"chosen": false, --是否选择该索引
"cause": "cost"
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */
} /* range_analysis */
}
] /* rows_estimation */
},
{
"considered_execution_plans": [
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`employees`",
"best_access_path": { --最优访问路径
"considered_access_paths": [ --最终选择的访问路径
{
"rows_to_scan": 10123,
"access_type": "scan", --访问类型:为scan,全表扫描
"resulting_rows": 10123,
"cost": 2052.6,
"chosen": true, --确定选择
"use_tmp_table": true
}
] /* considered_access_paths */
} /* best_access_path */,
"condition_filtering_pct": 100,
"rows_for_plan": 10123,
"cost_for_plan": 2052.6,
"sort_cost": 10123,
"new_cost_for_plan": 12176,
"chosen": true
}
] /* considered_execution_plans */
},
{
"attaching_conditions_to_tables": {
"original_condition": "(`employees`.`name` > 'a')",
"attached_conditions_computation": [
] /* attached_conditions_computation */,
"attached_conditions_summary": [
{
"table": "`employees`",
"attached": "(`employees`.`name` > 'a')"
}
] /* attached_conditions_summary */
} /* attaching_conditions_to_tables */
},
{
"clause_processing": {
"clause": "ORDER BY",
"original_clause": "`employees`.`position`",
"items": [
{
"item": "`employees`.`position`"
}
] /* items */,
"resulting_clause_is_simple": true,
"resulting_clause": "`employees`.`position`"
} /* clause_processing */
},
{
"reconsidering_access_paths_for_index_ordering": {
"clause": "ORDER BY",
"steps": [
] /* steps */,
"index_order_summary": {
"table": "`employees`",
"index_provides_order": false,
"order_direction": "undefined",
"index": "unknown",
"plan_changed": false
} /* index_order_summary */
} /* reconsidering_access_paths_for_index_ordering */
},
{
"refine_plan": [
{
"table": "`employees`"
}
] /* refine_plan */
}
] /* steps */
} /* join_optimization */
},
{
"join_execution": { --第三阶段:SQL执行阶段
"select#": 1,
"steps": [
] /* steps */
} /* join_execution */
}
] /* steps */
}
结论:全表扫描的成本低于索引扫描,所以mysql最终选择全表扫描
mysql> select * from employees where name > 'zzz' order by position;
mysql> SELECT * FROM information_schema.OPTIMIZER_TRACE;
查看trace字段可知索引扫描的成本低于全表扫描,所以mysql最终选择索引扫描
mysql> set session optimizer_trace="enabled=off"; --关闭trace
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
# 1.5、确定问题原因以及解决
- 多数慢SQL都跟索引有关,比如不加索引,索引不生效、不合理等
- 我们还可以优化SQL语句,比如一些in元素过多问题(分批),深分页问题(基于上一次数据过滤等),进行时间分段查询
- 如果单表数据量过大导致慢查询,可以让部分数据归档或者考虑分库分表+ES的方式
# 二、案例分析及原理
# count(*)查询优化
-- 临时关闭mysql查询缓存,为了查看sql多次执行的真实时间 set global query_cache_size=0; set global query_cache_type=0; EXPLAIN select count(1) from employees; EXPLAIN select count(id) from employees; EXPLAIN select count(name) from employees; EXPLAIN select count(*) from employees;1
2
3
4
5
6
7
8四个sql的执行计划一样,说明这四个sql执行效率应该差不多
字段有索引:count(*)≈count(1)>count(字段)>count(主键 id) //字段有索引,count(字段)统计走二级索引,二级索引存储数据比主键索引少,所以count(字段)>count(主键 id)
字段无索引:count(*)≈count(1)>count(主键 id)>count(字段) //字段没有索引count(字段)统计走不了索引,count(主键 id)还可以走主键索引,所以count(主键 id)>count(字段)
count(1)跟count(字段)执行过程类似,不过count(1)不需要取出字段统计,就用常量1做统计,count(字段)还需要取出字段,所以理论上count(1)比count(字段)会快一点。
count(*) 是例外,mysql并不会把全部字段取出来,而是专门做了优化,不取值,按行累加,效率很高,所以不需要用count(列名)或count(常量)来替代 count(*)。
为什么对于count(id),mysql最终选择辅助索引而不是主键聚集索引?因为二级索引相对主键索引存储数据更少,检索性能应该更高,mysql内部做了点优化(应该是在5.7版本才优化)。
# join关联查询优化
我们先聊一下MySQL的表关联算法:Nested-Loop Join 算法和 Block Nested-Loop Join 算法
嵌套循环连接 Nested-Loop Join(NLJ) 算法
从驱动表中读取符合条件一行数据,然后根据关联字段从被驱动表里查询满足条件的记录,然后将两条记录的结果合并。
-- t1表1W条数据,t2表100条数据(被驱动表的关联字段有索引) EXPLAIN select * from t1 inner join t2 on t1.a= t2.a;1
2整个过程大致如下(只会扫描200行数据):
1、从驱动表t2中读取一行数据
2、从第1步的记录中取出关联字段a,到被驱动表t2中查找数据
3、第1步和第2步中的结果数据合并
4、重复上面3步
整个过程会读取 t2 表的所有数据(扫描100行),然后遍历这每行数据中字段 a 的值,根据 t2 表中 a 的值索引扫描 t1 表中的对应行(扫描100次 t1 表的索引,1次扫描可以认为最终只扫描 t1 表一行完整数据,也就是总共 t1 表也扫描了100行)。因此整个过程扫描了 200 行
基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法
把驱动表的数据读入到 join_buffer 中,然后扫描被驱动表,把被驱动表每一行取出来跟 join_buffer 中的数据做对比
-- t1表1W条数据,t2表100条数据(被驱动表的关联字段无索引) EXPLAIN select * from t1 inner join t2 on t1.b= t2.b;1
2整个过程大致如下(只会扫描10100行数据,判断100*10000次):
1、把驱动表t2中所有数据放入到 join_buffer
2、把被驱动表 t1 中每一行取出来,跟 join_buffer 中的数据做对比
3、返回满足 join 条件的数据
整个过程对表 t1 和 t2 都做了一次全表扫描,因此扫描的总行数为10000(表 t1 的数据总量) + 100(表 t2 的数据总量) = 10100。并且 join_buffer 里的数据是无序的,因此对表 t1 中的每一行,都要做 100 次判断,所以内存中的判断次数是 100 * 10000= 100 万次
总结:对于关联sql的优化,小表驱动大表并且关联字段加索引
当使用left join时,左表是驱动表,右表是被驱动表,
当使用right join时,右表时驱动表,左表是被驱动表,
当使用join时,mysql会选择数据量比较小的表作为驱动表,大表作为被驱动表
当使用straight_join功能同join类似,但指定了左表是驱动表
# 最左前缀匹配原则
MySQl建立联合索引时,会遵循最左前缀匹配的原则,即最左优先
# 索引字段上使用(!= 或者 not in),索引可能失效
会认为cost成本太高,不如不走索引
# in元素过多问题
MySQL设置了个临界值(eq_range_index_dive_limit),5.6之后超过这个临界值后该列的cost就不参与计算了。因此会导致执行计划选择不准确。可以考虑分批查询或者union
默认是200,即in条件超过了200个数据,会导致in的代价计算存在问题,可能会导致Mysql选择的索引不准确
# in和exsits优化
in和exists的子查询,有一个原则:小表驱动大表,即小的数据集驱动大的数据集
-- in:当B表的数据集小于A表的数据集时,in优于exists select * from A where id in (select id from B) -- exists:当A表的数据集小于B表的数据集时,exists优于in select * from A where exists (select 1 from B where B.id = A.id)1
2
3
4
5# Order by与Group by优化
MySQL支持两种方式的排序filesort和index,Using index是指MySQL扫描索引本身完成排序。index 效率高,filesort效率低。group by和order by 字段上面加索引
Using filesort文件排序原理详解
单路排序:是一次性取出满足条件行的所有字段,然后在sort buffer中进行排序;
用trace工具可以看到sort_mode信息里显示< sort_key, additional_fields >或者< sort_key, packed_additional_fields >
双路排序(又叫回表排序模式):是首先根据相应的条件取出相应的排序字段和可以直接定位行数据的行 ID,然后在 sort buffer 中进行排序,排序完后需要再次取回其它需要的字段;
用trace工具可以看到sort_mode信息里显示< sort_key, rowid >
MySQL 通过比较系统变量 max_length_for_sort_data(默认1024字节) 的大小和需要查询的字段总大小来判断使用哪种排序模式。
如果 字段的总长度小于max_length_for_sort_data ,那么使用 单路排序模式;
如果 字段的总长度大于max_length_for_sort_data ,那么使用 双路排序模∙式。
总结:单路排序会把所有需要查询的字段都放到 sort buffer 中,而双路排序只会把主键和需要排序的字段放到 sort buffer 中进行排序,然后再通过主键回到原表查询需要的字段
# 深度分页优化
-- create_time字段有一个二级索引 select id,name,balance from account where create_time> '2020-09-19' limit 100000,10;1
2整个过程大致如下:
- 通过普通二级索引
idx_create_time,过滤create_time条件,找到满足条件的主键id。 - 通过主键
id,回到id主键索引树,找到满足记录的行,然后取出需要展示的列(回表过程) - 扫描满足条件的
100010行,然后扔掉前100000行,返回
优化方案:减少回表次数,使用标签记录法和延迟关联法
标签记录法
就是记录上一次查询到哪一条,下一次的查询带上上一次的id
select id,name,balance FROM account where id > 100000 limit 10;1延迟关联法
把条件转移到主键索引树,然后减少回表
select acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > '2020-09-19' limit 100000, 10) AS acct2 on acct1.id= acct2.id;1- 通过普通二级索引
参考:
EXPLAIN Output Format (opens new window)