
 JVM对象创建与内存分配机制
JVM对象创建与内存分配机制
# JVM对象创建与内存分配机制
# 一、对象创建过程

# 1. 类加载检查
虚拟机遇到一条new指令时,首先会去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那么必须先执行相应的类加载过程。
new指令对应到语言层面上讲是,new关键词、对象克隆、对象序列化等。
# 2. 分配内存
对象所需内存的大小在类加载完成后便可完全确定,会把一块确定大小的内存从Java堆中划分出来。
这个步骤需要考虑两个问题:
如何划分内存?
- 指针碰撞(Bump the Pointer)(默认用指针碰撞)
如果Java堆中的内存是绝对规整的,一边放已使用的内存,另一边放空闲的内存,中间放着一个指针作为分界点的指示器,那么分配内存就仅仅是把那个指针向空闲空间挪动一段与对象大小相等的距离。
- 空闲列表(Free List)
如果Java堆中的内存并不是规整的,已使用的内存和空闲的内存相互交错,那么就不能使用指针碰撞了。虚拟机维护了一个列表,用来记录哪些内存块是空闲的,在分配内存的时候就从列表中找到一块足够大的空间划分出来, 并且更新列表上的记录
选择哪种分配方式由Java堆是否规整决定, 而Java堆是否规整又由所采用的垃圾收集器是否带有空间压缩整理(Compact) 的能力决定。 因此, 当使用Serial、 ParNew等带压缩整理过程的收集器时, 系统采用的分配算法是指针碰撞, 既简单又高效; 而当使用CMS这种基于清除(Sweep) 算法的收集器时, 理论上就只能采用较为复杂的空闲列表来分配内存。
如何解决并发?
可能出现正在给对象A分配内存,指针还没来得及修改,同时对象B又使用了原来的指针来分配内存的情况
- CAS(compare and swap)
虚拟机采用CAS+失败重试的方式保证更新操作的原子性,对分配内存的动作进行同步处理。
- 本地线程分配缓冲(Thread Local Allocation Buffer,TLAB)
虚拟机为每个线程在Java堆中预先分配一小块内存(JVM会默认开启-XX:+UseTLAB,可以用-XX:TLABSize 指定TLAB大小)。
# 3. 初始化零值
虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),这一步操作保证了对象的实例字段在Java代码中可以不赋初始值就能直接使用,程序能访问到这些字段的数据类型所对应的零值。
如果使用TLAB,这一工作过程也可以提前至TLAB分配时进行。
# 4. 设置对象头
初始化零值之后,虚拟机需要对对象进行一些必要的设置
例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的GC分代年龄等信息。这些信息都是存放在对象的对象头Object Header之中。
# 5. 执行init方法
属性赋值和执行构造方法
# 二、对象内存分配
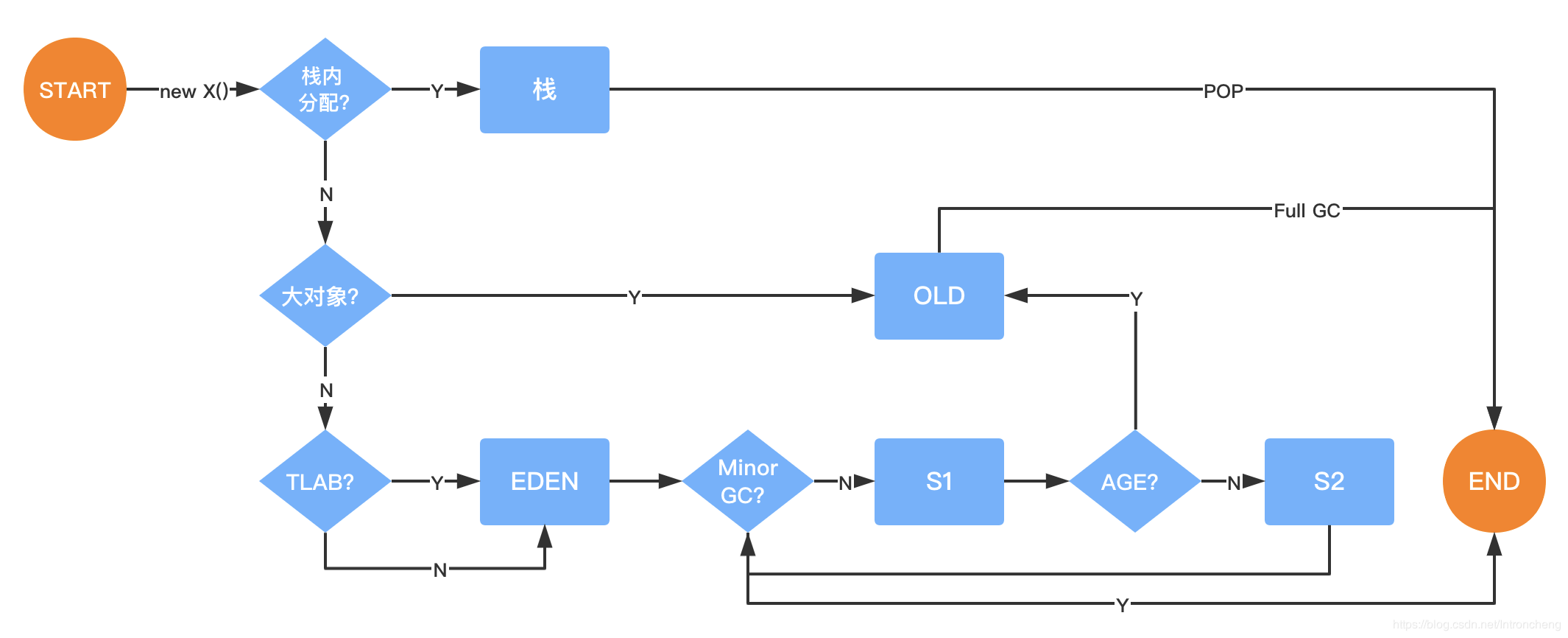
# 1. 对象栈上分配
Java 中的对象基本上都是在堆上进行分配的,但是也有可能在栈上分配。如果JVM通过逃逸分析确定该对象不会被外部访问,那么就可以在栈上分配内存,这样该对象所占用的内存空间就可以随栈帧出栈而销毁,减少了临时对象在堆内分配的数量,也减轻了垃圾回收的压力。
逃逸分析:就是分析对象动态作用域,当一个对象在方法中被定义后,它可能会被外部方法所引用,例如作为调用参数传递到其他地方中。
JVM对于这种情况可以通过开启逃逸分析参数(JDK7默认开启 -XX:+DoEscapeAnalysis)来优化对象内存分配位置,使其通过标量替换优先分配在栈上(栈上分配)
标量替换:如果 JVM 通过逃逸分析确定该对象不会被外部访问,并且对象可以被进一步分解时,JVM不会创建这个对象,而是将这个对象分解成若干个被这个方法使用的局部变量,这样就不会因为没有一大块连续空间导致对象内存不够分配。(JDK7默认开启 -XX:+EliminateAllocations)。
标量与聚合量:
标量是不可被进一步分解的量。
Java 的基本数据类型就是标量(如:int,long等基本数据类型以及reference类型等),
聚合量就是可以被进一步分解的量。
Java 中对象就是可以被进一步分解的聚合量。
栈上分配示例:
/**
* 栈上分配,标量替换
* 代码调用了1亿次test1(),如果是分配到堆上,大概需要1GB以上堆空间,如果堆空间小于该值,必然会触发GC。
*
* 使用如下参数不会发生GC
* -Xmx15m -Xms15m -XX:+DoEscapeAnalysis -XX:+PrintGC -XX:+EliminateAllocations
* 使用如下参数都会发生大量GC
* -Xmx15m -Xms15m -XX:-DoEscapeAnalysis -XX:+PrintGC -XX:+EliminateAllocations
* -Xmx15m -Xms15m -XX:+DoEscapeAnalysis -XX:+PrintGC -XX:-EliminateAllocations
*/
public class AllotOnStack {
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
test1();
}
long end = System.currentTimeMillis();
System.out.println(end - start);
}
private static void test1() {
User user = new User();
user.setId(1);
user.setName("hello");
}
private static User test2() {
User user = new User();
user.setId(1);
user.setName("hello");
return user;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
很显然test1方法中的user对象被返回了,这个对象的作用域范围不确定,test2方法中的user对象我们可以确定当方法结束这个对象就可以认为是无效对象了,对于这样的对象我们其实可以将其分配在栈内存里,让其在方法结束时跟随栈内存一起被回收掉。
结论:栈上分配依赖于逃逸分析和标量替换
# 2. 大对象直接进入老年代
大对象就是需要大量连续内存空间的对象(比如:字符串、数组),为了避免大对象在年轻代的复制操作而降低效率,对象超过设置大小会直接进入老年代。
JVM参数 -XX:PretenureSizeThreshold 可以设置大对象的大小,这个参数只在 Serial 和ParNew两个收集器下有效。
比如设置JVM参数:-XX:PretenureSizeThreshold=1000000 (单位是字节) -XX:+UseSerialGC ,再执行下上面的第一个程序会发现大对象直接进了老年代
# 3. 对象在Eden区分配
大多数情况下,对象在 Eden 区分配。当 Eden 区没有足够空间进行分配时,虚拟机将发起一次Minor GC。
Minor GC和Full GC 有什么不同呢?
- Minor GC/Young GC:指发生新生代的的垃圾收集动作,Minor GC非常频繁,回收速度一般也比较快。
- Major GC/Full GC:一般会回收老年代 ,年轻代,方法区的垃圾,Major GC的速度一般会比Minor GC的慢10倍以上。
Eden与Survivor区默认8:1:1(会自动变化,-XX:+UseAdaptiveSizePolicy(默认开启)
大量的对象被分配在eden区,eden区满了后会触发minor gc,可能会有99%以上的对象成为垃圾被回收掉,剩余存活的对象会被挪到为空的那块survivor区,下一次eden区满了后又会触发minor gc,把eden区和survivor区垃圾对象回收,把剩余存活的对象一次性挪动到另外一块为空的survivor区,因为新生代的对象都是朝生夕死的,存活时间很短,所以JVM默认的8:1:1的比例是很合适的,让eden区尽量的大,survivor区够用即可
示例:
//添加运行JVM参数: -XX:+PrintGCDetails
public class GCTest {
public static void main(String[] args) throws InterruptedException {
byte[] allocation1, allocation2/*, allocation3, allocation4, allocation5, allocation6*/;
allocation1 = new byte[60000*1024];
//allocation2 = new byte[8000*1024];
/*allocation3 = new byte[1000*1024];
allocation4 = new byte[1000*1024];
allocation5 = new byte[1000*1024];
allocation6 = new byte[1000*1024];*/
}
}
运行结果:
Heap
PSYoungGen total 76288K, used 65536K [0x000000076b400000, 0x0000000770900000, 0x00000007c0000000)
eden space 65536K, 100% used [0x000000076b400000,0x000000076f400000,0x000000076f400000)
from space 10752K, 0% used [0x000000076fe80000,0x000000076fe80000,0x0000000770900000)
to space 10752K, 0% used [0x000000076f400000,0x000000076f400000,0x000000076fe80000)
ParOldGen total 175104K, used 0K [0x00000006c1c00000, 0x00000006cc700000, 0x000000076b400000)
object space 175104K, 0% used [0x00000006c1c00000,0x00000006c1c00000,0x00000006cc700000)
Metaspace used 3342K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 361K, capacity 388K, committed 512K, reserved 1048576K
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
我们可以看出eden区内存几乎已经被分配完全(即使程序什么也不做,新生代也会使用至少几M内存)。假如我们再为allocation2分配内存会出现什么情况呢?
//添加运行JVM参数: -XX:+PrintGCDetails
public class GCTest {
public static void main(String[] args) throws InterruptedException {
byte[] allocation1, allocation2/*, allocation3, allocation4, allocation5, allocation6*/;
allocation1 = new byte[60000*1024];
allocation2 = new byte[8000*1024];
/*allocation3 = new byte[1000*1024];
allocation4 = new byte[1000*1024];
allocation5 = new byte[1000*1024];
allocation6 = new byte[1000*1024];*/
}
}
运行结果:
[GC (Allocation Failure) [PSYoungGen: 65253K->936K(76288K)] 65253K->60944K(251392K), 0.0279083 secs] [Times: user=0.13 sys=0.02, real=0.03 secs]
Heap
PSYoungGen total 76288K, used 9591K [0x000000076b400000, 0x0000000774900000, 0x00000007c0000000)
eden space 65536K, 13% used [0x000000076b400000,0x000000076bc73ef8,0x000000076f400000)
from space 10752K, 8% used [0x000000076f400000,0x000000076f4ea020,0x000000076fe80000)
to space 10752K, 0% used [0x0000000773e80000,0x0000000773e80000,0x0000000774900000)
ParOldGen total 175104K, used 60008K [0x00000006c1c00000, 0x00000006cc700000, 0x000000076b400000)
object space 175104K, 34% used [0x00000006c1c00000,0x00000006c569a010,0x00000006cc700000)
Metaspace used 3342K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 361K, capacity 388K, committed 512K, reserved 1048576K
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
简单解释一下为什么会出现这种情况: 因为给allocation2分配内存的时候eden区内存几乎已经被分配完了,我们刚刚讲了当Eden区没有足够空间进行分配时,虚拟机将发起一次Minor GC,GC期间虚拟机又发现allocation1无法存入Survior空间,所以只好把新生代的对象提前转移到老年代中去,老年代上的空间足够存放allocation1,所以不会出现Full GC。执行Minor GC后,后面分配的对象如果能够存在eden区的话,还是会在eden区分配内存。可以执行如下代码验证:
public class GCTest {
public static void main(String[] args) throws InterruptedException {
byte[] allocation1, allocation2, allocation3, allocation4, allocation5, allocation6;
allocation1 = new byte[60000*1024];
allocation2 = new byte[8000*1024];
allocation3 = new byte[1000*1024];
allocation4 = new byte[1000*1024];
allocation5 = new byte[1000*1024];
allocation6 = new byte[1000*1024];
}
}
运行结果:
[GC (Allocation Failure) [PSYoungGen: 65253K->952K(76288K)] 65253K->60960K(251392K), 0.0311467 secs] [Times: user=0.08 sys=0.02, real=0.03 secs]
Heap
PSYoungGen total 76288K, used 13878K [0x000000076b400000, 0x0000000774900000, 0x00000007c0000000)
eden space 65536K, 19% used [0x000000076b400000,0x000000076c09fb68,0x000000076f400000)
from space 10752K, 8% used [0x000000076f400000,0x000000076f4ee030,0x000000076fe80000)
to space 10752K, 0% used [0x0000000773e80000,0x0000000773e80000,0x0000000774900000)
ParOldGen total 175104K, used 60008K [0x00000006c1c00000, 0x00000006cc700000, 0x000000076b400000)
object space 175104K, 34% used [0x00000006c1c00000,0x00000006c569a010,0x00000006cc700000)
Metaspace used 3343K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 361K, capacity 388K, committed 512K, reserved 1048576K
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 4. 对象动态年龄判断机制
Survivor区现在有一批对象,如果年龄1+年龄2+年龄n的多个年龄对象总和超过了Survivor区域的50%(-XX:TargetSurvivorRatio可以指定),那么就会把年龄n(含)以上的对象都放入老年代。
这个规则其实是希望那些可能是长期存活的对象,尽早进入老年代。对象动态年龄判断机制一般是在minor gc之后触发的。
# 5. 长期存活的对象进入老年代
每个对象的对象头中存储了GC分代年龄信息,对象每熬过一次 MinorGC,年龄就增加1岁,当它的年龄增加到一定程度,就会被晋升到老年代(-XX:MaxTenuringThreshold ,默认为15岁,CMS收集器默认6岁,不同的垃圾收集器会略微有点不同)
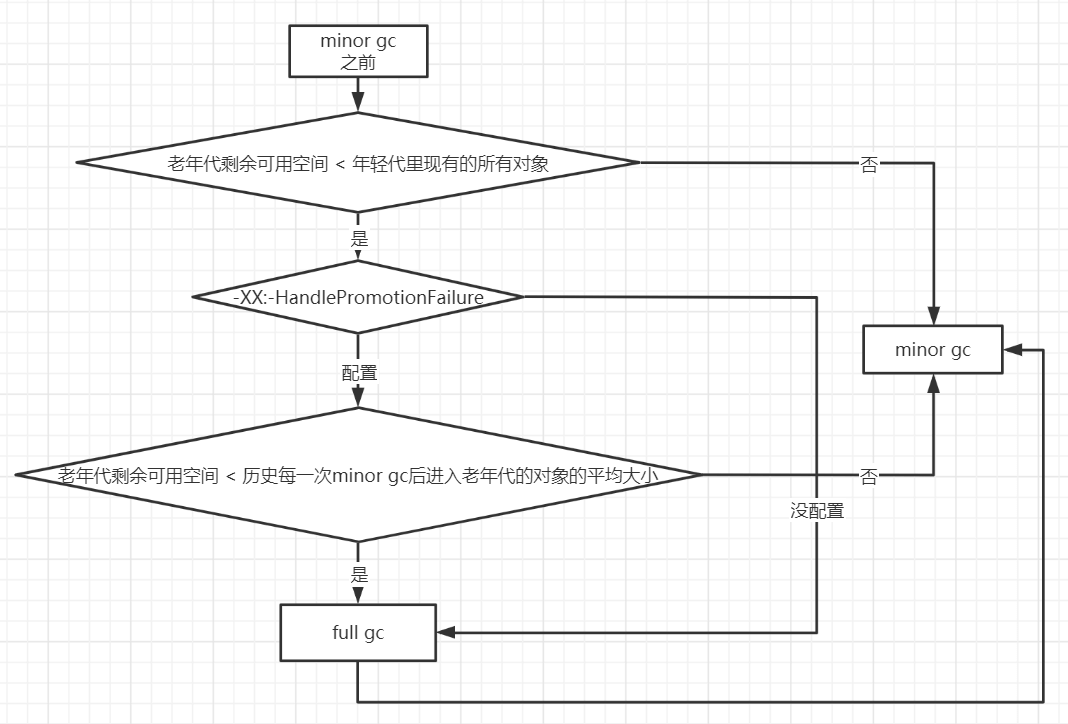
# 6. 老年代空间分配担保机制
年轻代每次Minor GC之前,JVM都会计算下老年代剩余可用空间
如果这个可用空间小于年轻代所有对象大小之和(包括垃圾对象),那么再判断这个可用空间是否大于之前每一次Minor GC后进入老年代的对象的平均大小(-XX:-HandlePromotionFailure”(jdk1.8默认就设置了))。
如果大于的话,那么触发一次Minor GC,否则触发一次Full GC。
# 三、对象内存回收
# 3.1 如何判断一个对象是垃圾对象?
# 3.1.1 引用计数法
给对象中添加一个引用计数器,每当有一个地方引用它,计数器就加1;当引用失效,计数器就减1;
缺点:它很难解决对象之间相互循环引用的问题
随笔:如何解决循环引用问题
1、利用写屏障,当发生属性赋值的时候,检查是否存在循环引用,记录下来
2、GC后,新生代99%的对象是垃圾对象,只需要检查存活的对象是否存在循环引用
扩展:循环引用的检查方式?快慢指针、哈希表
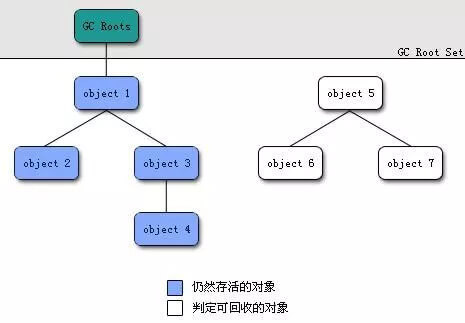
# 3.1.2 可达性分析算法
把从GC Roots开始遍历整个对象图过程中,扫描到的对象都标记为非垃圾对象,其余未标记的对象就是垃圾对象
GC Roots:方法区的静态变量、线程栈的局部变量、本地方法栈的变量等等
# 3.2 如何判断一个类是无用的类?
对方法区进行回收,主要回收的是无用的类,那么如何判断一个类是无用的类呢?
- 这个类所有的对象实例都已经被回收。
- 加载这个类的 ClassLoader 已经被回收。
- 这个类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
# 3.3 常见的引用类型
java的引用类型分为四种:强引用、软引用、弱引用、虚引用
- 强引用:普通的变量引用
public static User user = new User();
- 软引用:SoftReference包裹的对象,正常情况下不会被回收,但是GC做完后发现释放不出空间存放新的对象,就会把这些软引用的对象回收掉。软引用可用来实现内存敏感的高速缓存。
public static SoftReference<User> user = new SoftReference<User>(new User());
弱引用:WeakReference包裹的对象,弱引用跟没引用差不多,GC会直接回收掉,ThreadLocal里面有使用到弱引用。
public static WeakReference<User> user = new WeakReference<User>(new User());1SoftReference<String> softReference = new SoftReference<>(new String("softReference12312")); WeakReference<String> weakReference = new WeakReference<>(new String("weakReference12312")); System.out.println("==========GC前=========="); System.out.println("softReference = " + softReference.get()); System.out.println("weakReference = " + weakReference.get()); System.gc(); System.out.println("==========GC后=========="); System.out.println("softReference = " + softReference.get()); System.out.println("weakReference = " + weakReference.get()); ==========GC前========== softReference = softReference12312 weakReference = weakReference12312 ==========GC后========== softReference = softReference12312 weakReference = null1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16虚引用:PhantomReference包裹的对象,它是最弱的一种引用关系,几乎不用
# 3.4 finalize()方法最终判定对象是否存活
即使在可达性分析算法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑”阶段,要真正宣告一个对象死亡,至少要经历再次标记过程。
标记的前提是对象在进行可达性分析后发现没有与GC Roots相连接的引用链。
1. 第一次标记并进行一次筛选。
筛选的条件是此对象是否有必要执行finalize()方法。
当对象没有覆盖finalize方法,对象将直接被回收。
2. 第二次标记
如果这个对象覆盖了finalize方法,finalize方法是对象脱逃死亡命运的最后一次机会,如果对象要在finalize()中成功拯救自己,只要重新与引用链上的任何的一个对象建立关联即可,譬如把自己赋值给某个类变量或对象的成员变量,那在第二次标记时它将移除出“即将回收”的集合。如果对象这时候还没逃脱,那基本上它就真的被回收了。
注意:一个对象的finalize()方法只会被执行一次,也就是说通过调用finalize方法自我救命的机会就一次。
示例代码:
public class OOMTest {
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
int i = 0;
int j = 0;
while (true) {
list.add(new User(i++, UUID.randomUUID().toString()));
new User(j--, UUID.randomUUID().toString());
}
}
}
//User类需要重写finalize方法
@Override
protected void finalize() throws Throwable {
OOMTest.list.add(this);
System.out.println("关闭资源,userid=" + id + "即将被回收");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
finalize()方法的运行代价高昂, 不确定性大, 无法保证各个对象的调用顺序, 如今已被官方明确声明为不推荐使用的语法。 有些资料描述它适合做“关闭外部资源”之类的清理性工作, 这完全是对finalize()方法用途的一种自我安慰。 finalize()能做的所有工作, 使用try-finally或者其他方式都可以做得更好、更及时, 所以建议大家完全可以忘掉Java语言里面的这个方法。
# 3.5 对象的内存布局
在HotSpot中,对象在内存中存储的布局可以分为3块区域:对象头(Header)、 实例数据(Instance Data)和对齐填充(Padding)。
关于对齐填充:对于大部分处理器,对象以8字节整数倍来对齐填充都是最高效的存取方式。
其中对象头的结构如下:
Mark Word 标记字段 :存储对象自身的运行时数据,例如:哈希码(HashCode)、GC分代年龄(4bit)、锁状态标志(2bit)、线程持有的锁、偏向线程ID、偏向时间戳等。(32位占4字节,64位占8字节)
随笔:GC分代年龄为4bit,因此不会超过2^4-1=15
Klass Pointer 类型指针 :指向类元数据信息的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
数组长度:4字节,只有数组对象才有
32位对象头

64位对象头

对象头在hotspot的C++源码markOop.hpp文件里的注释如下:
// Bit-format of an object header (most significant first, big endian layout below):
//
// 32 bits:
// --------
// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
// size:32 ------------------------------------------>| (CMS free block)
// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
//
// 64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)
//
// unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
// JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
// narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
// unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 3.6. 对象的访问定位
我们的Java程序会通过栈上的reference数据来操作堆上的具体对象,主流的访问方式有句柄和直接指针两种:
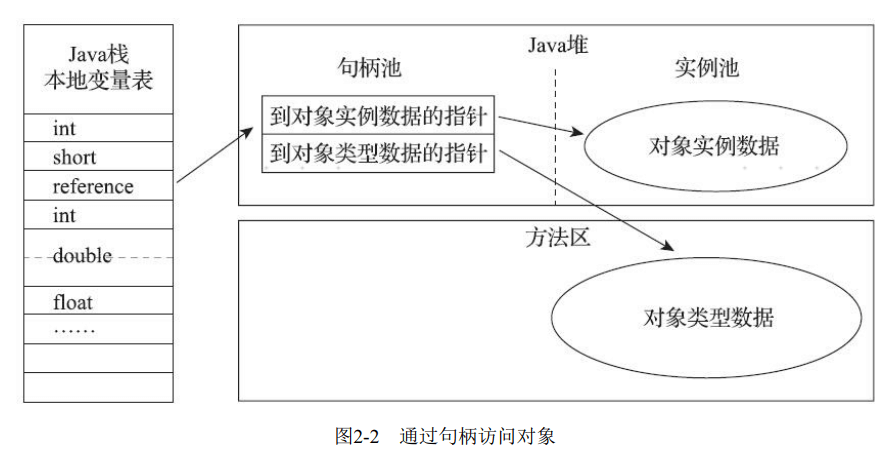
句柄
如果使用句柄访问的话,reference中存储的就是对象的句柄地址。Java堆会划分出一块内存来作为句柄池,句柄中包含了对象实例数据的指针和对象类型数据的指针。它的好处是reference中存储的是稳定的句柄地址, 在对象被移动(垃圾收集时) 时只会改变句柄中的实例数据指针,而reference本身不需要被修改 , 如下图所示。
直接指针
如果使用直接指针访问的话,reference中存储的就是对象地址, 对象中包含了对象类型数据的指针 。它的好处是速度更快, 省去了一次指针定位的时间开销。
如果只是访问对象本身的话, 就不需要多一次间接访问的开销
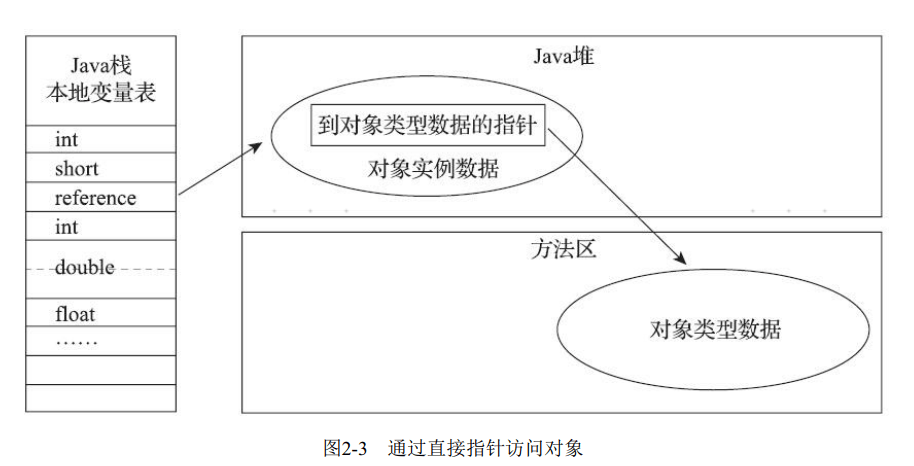
由于对象访问在Java中非常频繁, 因此这类开销积少成多也是一项极为可观的执行成本, 就本书讨论的主要虚拟机HotSpot而言, 它主要使用第二种方式进行对象访问, 但从整个软件开发的范围来看, 在各种语言、 框架中使用句柄来访问的情况也十分常见。
# 3.7 对象大小与指针压缩
对象大小可以用jol-core包查看,引入依赖
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
2
3
4
5
import org.openjdk.jol.info.ClassLayout;
/**
* 计算对象大小
*/
public class JOLSample {
public static void main(String[] args) {
ClassLayout layout = ClassLayout.parseInstance(new Object());
System.out.println(layout.toPrintable());
System.out.println();
ClassLayout layout1 = ClassLayout.parseInstance(new int[]{});
System.out.println(layout1.toPrintable());
System.out.println();
ClassLayout layout2 = ClassLayout.parseInstance(new A());
System.out.println(layout2.toPrintable());
}
// -XX:+UseCompressedOops 默认开启的压缩所有指针
// -XX:+UseCompressedClassPointers 默认开启的压缩对象头里的类型指针Klass Pointer
// Oops : Ordinary Object Pointers
public static class A {
//8B mark word
//4B Klass Pointer 如果关闭压缩-XX:-UseCompressedClassPointers或-XX:-UseCompressedOops,则占用8B
int id; //4B
String name; //4B 如果关闭压缩-XX:-UseCompressedOops,则占用8B
byte b; //1B
Object o; //4B 如果关闭压缩-XX:-UseCompressedOops,则占用8B
}
}
运行结果:
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1) //mark word
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) //mark word
8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243) //Klass Pointer
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
[I object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 6d 01 00 f8 (01101101 00000001 00000000 11111000) (-134217363)
12 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
16 0 int [I.<elements> N/A
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
com.tuling.jvm.JOLSample$A object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 61 cc 00 f8 (01100001 11001100 00000000 11111000) (-134165407)
12 4 int A.id 0
16 1 byte A.b 0
17 3 (alignment/padding gap)
20 4 java.lang.String A.name null
24 4 java.lang.Object A.o null
28 4 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 3 bytes internal + 4 bytes external = 7 bytes total
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
什么是指针压缩?
在 JVM 中,32位地址最大支持4G内存(2的32次方),可以在对象的指针存入堆内存的时候进行压缩编码、在取出到cpu寄存器的时候进行解码(对象指针在堆中是32位,在寄存器中是35位,2的35次方=32G),使 JVM 只用32位地址就可以支持更大的内存配置
-XX:+UseCompressedOops(默认开启),compressed--压缩、oop(ordinary object pointer)--对象指针
为什么要使用指针压缩?
在64位平台的HotSpot中使用32位指针(实际存储用64位),内存使用会多出1.5倍左右,GC会承受较大的压力
堆内存小于4G时,不需要启用指针压缩,jvm会直接去除高32位地址,即使用低虚拟地址空间
指针压缩的原理?
Java 默认是 8 字节对齐的内存,在描述内存的时候,不用从 0 开始描述到 8(就是根本不需要定位到之后的1,2,3,4,5,6,7)因为对象起止肯定都是 8 的整数倍。所以,2^32 字节如果一个1代表8字节的话,那么最多可以描述 2^32 * 8 字节也就是 32 GB 的内存。
Java 默认是 8 字节对齐的内存,也就是一个对象占用的空间,必须是 8 字节的整数倍,不足的话会填充到 8 字节的整数倍。如果配置最大堆内存超过 32 GB(当 JVM 是 8 字节对齐),那么压缩指针会失效。 但是,这个 32 GB 是和字节对齐大小相关的,也就是
-XX:ObjectAlignmentInBytes配置的大小(默认为8字节,也就是 Java 默认是 8 字节对齐)。-XX:ObjectAlignmentInBytes可以设置为 8 的整数倍,最大 128。也就是如果配置-XX:ObjectAlignmentInBytes为 24,那么配置最大堆内存超过 96 GB 压缩指针才会失效。按更大对齐可以寻址更大空间,但是浪费就更大了